
Mani Doraisamy
Developer forever
| FR
Computers follow exact rules. They understand logic like "Delhi" ≠ "Chennai" or "Population of Delhi" > 30 million. However, they struggle to understand the concept of similarity (≈). For example, to us, "Delhi" ≈ "Noida" because both are part of the National Capital Region, but computers can't grasp that naturally. To make computers as intelligent as humans, we first need to teach them the concept of similarity (≈). How do we do that?
It's all about distance
 In the Tamil movie Puthumaipithan, Vadivelu plays the role of a politician who explains to journalists why places near Delhi have more political influence than Chennai. His answer? "It’s distance." He goes on to propose moving Chennai closer to Delhi to gain more influence. While this idea may seem absurd at first, it's actually similar to how AI works. AI uses 'distance' to understand how close or similar different entities are. In this post, I'll show how AI applies this concept to determine similarity between different entities like cities. First, we'll look at how Noida is closer to Delhi, then see how Chennai can be considered closer to Delhi depending on the context.
In the Tamil movie Puthumaipithan, Vadivelu plays the role of a politician who explains to journalists why places near Delhi have more political influence than Chennai. His answer? "It’s distance." He goes on to propose moving Chennai closer to Delhi to gain more influence. While this idea may seem absurd at first, it's actually similar to how AI works. AI uses 'distance' to understand how close or similar different entities are. In this post, I'll show how AI applies this concept to determine similarity between different entities like cities. First, we'll look at how Noida is closer to Delhi, then see how Chennai can be considered closer to Delhi depending on the context.
For a politician, Noida ≈ Delhi
 Let's take a politician like Vadivelu as our first example. For a politician, the closer the two cities are, the more similar they are in terms of language, culture, and voting patterns. If you provide a computer with the latitude and longitude of Delhi, Noida, and Chennai, it can calculate the distances between the cities. Based on distance, it can conclude that "Noida" is closer to "Delhi" than "Chennai." Computers excel at calculating exact distances, which helps them determine which cities are similar in this specific context. Computers use machine learning (ML) algorithms to calculate the distance between entities like cities to determine their similarity. We train these algorithms to focus only on the characteristics relevant to a specific use case—such as latitude and longitude for physical distance.
Let's take a politician like Vadivelu as our first example. For a politician, the closer the two cities are, the more similar they are in terms of language, culture, and voting patterns. If you provide a computer with the latitude and longitude of Delhi, Noida, and Chennai, it can calculate the distances between the cities. Based on distance, it can conclude that "Noida" is closer to "Delhi" than "Chennai." Computers excel at calculating exact distances, which helps them determine which cities are similar in this specific context. Computers use machine learning (ML) algorithms to calculate the distance between entities like cities to determine their similarity. We train these algorithms to focus only on the characteristics relevant to a specific use case—such as latitude and longitude for physical distance.
For an entrepreneur, Chennai ≈ Delhi
 Now, consider an entrepreneur looking to expand their business. They want to find a city similar to "Delhi." In this scenario, you would provide different characteristics like "tier" (the size of the city) and "population." This data would show that "Chennai" is more similar to "Delhi" than "Noida" because both Chennai and Delhi are tier-1 cities with similar populations. In this case, the 'distance' doesn't refer to physical proximity but rather to how similar they are in characteristics like population and city size. This ability to find similarities using machine learning helps computers perform pattern matching. This is similar to how humans do pattern recognition and represents a foundational step towards achieving human-like intelligence.
Now, consider an entrepreneur looking to expand their business. They want to find a city similar to "Delhi." In this scenario, you would provide different characteristics like "tier" (the size of the city) and "population." This data would show that "Chennai" is more similar to "Delhi" than "Noida" because both Chennai and Delhi are tier-1 cities with similar populations. In this case, the 'distance' doesn't refer to physical proximity but rather to how similar they are in characteristics like population and city size. This ability to find similarities using machine learning helps computers perform pattern matching. This is similar to how humans do pattern recognition and represents a foundational step towards achieving human-like intelligence.
Narrow AI
The characteristics such as latitude/longitude provided to an ML algorithm depend on the use case—whether it’s for a politician to compete in an election or an entrepreneur to expand their company. In both cases, calculating similarity requires a lot of data, such as knowing the details of all the cities. If you don't have enough data, the algorithm won't work correctly. This is known as the "cold start problem" in machine learning. This was what we tried to solve at our startup, Guesswork, back in 2013. By focusing on one specific use case—customer information—we could pre-train our ML model and solve the cold start problem. Hence, these models were called narrow AI.
General Purpose AI
The current AI era has given rise to a new breed of models called Large Language Models (LLMs). These models solve the cold start problem differently. They are trained on vast amounts of information available on the internet. They understand thousands of characteristics about each word, such as "Delhi" or "Chennai." Instead of using simple two-dimensional charts, LLMs represent words like "Delhi" and "Chennai" in a multidimensional space, where each dimension captures a specific characteristic of the cities. They can then calculate the distance between words in that space to understand similarities—even without specific training data.
But there is still a challenge: How do you make sure the model focuses on only certain characteristics? For example, if you’re a politician trying to find a similar city for an election, the model should focus on latitude and longitude to calculate the distance. But if you’re an entrepreneur, it should focus on tier and population. How do you do that?
Prompting: With prompting, you instruct the model in plain English to focus on the right characteristics. For example, if a politician asks the model to find a city similar to Delhi for an election, the model might consider that latitude and longitude are important because being close could influence political support. Therefore, it would suggest Noida over Chennai.
Fine-Tuning: In fine-tuning, you train the model with examples. This might look similar to ML models from the past, but it is different. Traditional ML models start with no knowledge. But, fine-tuned models already have knowledge from the internet and can focus on characteristics mentioned in the examples. In our case, it knows about the language and culture of the cities, but it will pay more attention to latitude and longitude because we emphasized them in the examples. In short, traditional ML models need a lot of examples, and prompting can be unpredictable without examples. Fine-tuning balances both and gives predictable results with fewer examples.
But LLMs can do more than just find similar cities—they can also explain why. For example, they can explain why Chennai might be better for starting a business than Noida, all in plain English. This works a bit like Google Translate. In Google Translate, you provide a fact about Delhi and ask it to translate it into another language. With LLMs, you provide a fact about Delhi and ask it to transform that fact for Chennai. This kind of transformation is called generative AI, which is used in tools like ChatGPT.
Summary
Computers follow exact rules, so we call them deterministic. But when computers understand ≈, we call them probabilistic. This is because they calculate the distance between two entities and conclude that they are “probably” similar. As long as a computer can measure how "close" two entities are, it can determine if they are similar, understand their connection, and provide meaningful answers. This simple idea of similarity (≈) was a major stepping stone for computers, enabling them to make decisions that are not just logical but also intuitive—much like humans do. AI has taken that concept and turned it into something magical—whether it's answering our questions or helping us make decisions—reshaping the world as we know it.
When you create a leave application form using Google Forms, you notice how effortless it is to add fields, one by one. However, with an AI-enabled form builder like Formfacade, the form is generated automatically as soon as you enter the title “leave application form.” This marks a fundamental shift in how products are being built. Instead of simplifying form creation on a blank canvas, products are now pre-creating forms, giving users a tailored starting point.
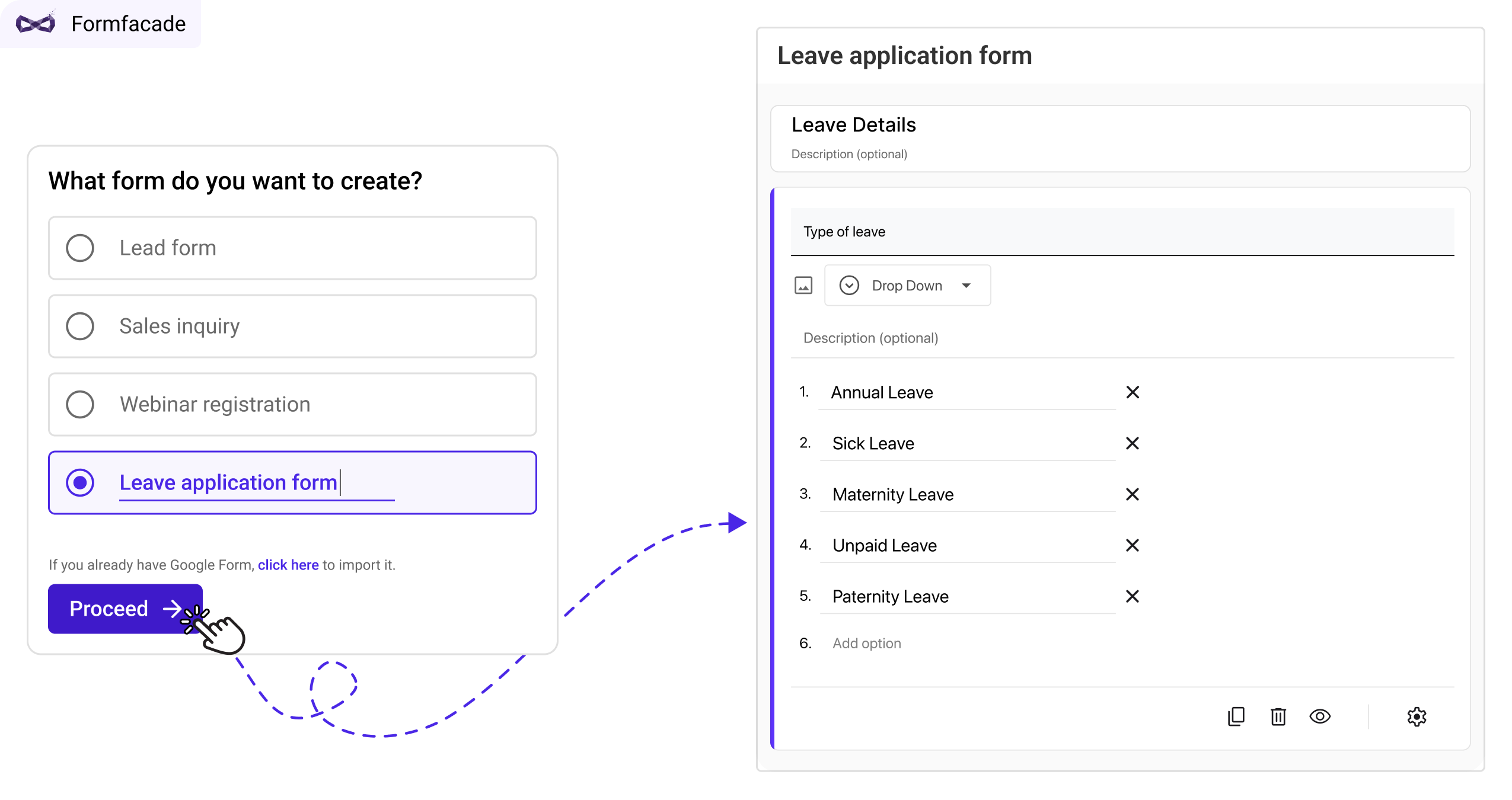
Prompting will replace templates in B2B products
In the past, products like Google Forms addressed form creation by offering a variety of templates. Due to the wide range of user needs, many of these templates were crowdsourced from users, leading to inconsistent quality and difficulty in finding the right one. In the future, products will use a handful of base templates as a “seed” for AI to generate customized templates for each user. At Formfacade, we use Promptrepo to create AI model from our pre-existing form templates. This model is used to pre-create form automatically when the user enters a form title.
This shift fundamentally changes the onboarding experience. The focus will no longer be on teaching users to add fields to a blank canvas. Instead, products will make it easy to edit pre-created forms (e.g., "Add final polish" in ChatGPT 4o with canvas). In both scenarios—form title during creation and form fields during editing—the form itself acts as the prompt, rather than relying on user-entered prompt as seen in many AI-enabled apps today. This change applies not only to form builders but also to other platforms, from Canva to WordPress. Eventually, these products will be redesigned—or replaced—by new solutions that offer pre-filled canvas ready for editing, rather than blank slates requiring manual setup.
Agents will replace integration in consumer products
While prompting helps prefill information within a single app, AI agents will work across multiple apps to prefill information. Consider planning a trip to attend a conference. Typically, you would need to interact with separate apps for booking the conference, airline tickets, and hotel accommodations. In the past, integrations were built between each of these applications to avoid reentering the same information. In an AI-enabled future, agents will work across these platforms based on a single input, dynamically building the necessary integration between user-facing apps on the fly.
AI agents will handle multiple applications behind the scenes, allowing you to interact through one interface. This seamless, cross-platform experience could unfold over multiple days, with a single app serving as the central point of your journey rather than requiring you to juggle multiple apps. The conference booking app, for instance, could become the origin of your trip, coordinating all necessary bookings. Additionally, this app could collect affiliate fees from other applications involved in the process.
Summary
Ten years ago, I explained how software was augmented with hardware in the SaaS era, leading to new wave of products like Salesforce. And, I predicted that the next wave would augment intelligence with software using AI. Specifically, AI would automate tasks—such as prefilled leads in CRM systems—that required human intelligence. Today, with the rise of generative AI, we are moving in that direction, although we may have been influenced too much by the success of ChatGPT. Instead of focusing on prefilling information, we are adding chat interfaces to all products, even when they may be unnecessary. I believe that once we refocus on solving core use cases rather than simply emulating ChatGPT's success, we will see this shift:
Prompting will redefine B2B SaaS onboarding by replacing blank canvas with tailored form or content based on minimal user input like form title. Meanwhile, AI agents will integrate multiple apps on the fly, enabling users to accomplish tasks across products from a single interface. In essence, prompting will redefine B2B products, while agents will redefine consumer products.
Remember when you emailed your manager for sick leave, and they approved it with a kind "take care"? Then one day, instead of a warm response, you got a link to a leave request form from HR. Suddenly, what used to be a human interaction turned into a cold, bureaucratic process. Why do companies do this? Why turn simple conversations into forms?
Users need chain of thought more than AI
While AI companies are building "chain of thought" into their language models, we are the ones who need it the most. Whether it's filling out a leave request form (painful) or a Y Combinator application (thoughtful), the questions in the form make us think. If we sent them through email, we wouldn't consider all the necessary details. We might say, "I'm feeling unwell, taking the next two days off," and that feels natural to us. But for the HR department, there's much more they need to know—like how many leave days you have left, whether it affects payroll, and if your manager has approved it.
Companies turn conversations into structured forms because it streamlines information gathering. Instead of HR needing to follow up for missing details, a form can capture all this information upfront, reducing delays and confusion. As we automate these processes with AI, this balance must be maintained. AI should not only convert our conversation into a leave request; it should also prompt us for missing information, similar to required fields and validations in a form.
Chain of thought in business logic
This need for structured data doesn't stop at how we provide information; it also influences how we process it. For instance, if someone has exhausted their leave balance, applying simple, deterministic rules to structured data yields better results than relying on AI models that use probabilistic logic. Deterministic logic rules are more reliable than AI that relies on probabilistic reasoning. This is especially important in regulated industries like insurance, where the step-by-step logic leading to a decision is not only preferable but mandatory.

Extending chain of thought to UI
But how do you communicate this to the user? Should AI respond like a screen reader, dictating these details step by step? Or should it show a pre-filled form, visually presenting the information all at once? The answer is clear — user interface is far more efficient than a chat response because it offers clarity and speed of comprehension. Think about ordering a cab on Uber. Instead of receiving chat updates about the cars around you, a UI that shows the cars on a map is far more efficient and clear. This is where generative AI often falls short—chatting endlessly when a well-designed interface would be more effective.
Semantic AI
At Promptrepo, we call this approach 'Semantic AI' — it's about understanding the meaning behind our words to extract structured data from conversations and presenting it in a modality that's easier for you. Semantic AI will identify key details like dates and reasons when you send an email about taking leave. It will then automatically populate the necessary fields in a leave request form for you to verify and submit. This way, AI assists in maintaining our natural communication style while ensuring all required information is captured.
![]() Once the generative AI hype settles, we believe the true power of AI will lie in extracting structured data rather than generating a "word salad." As AI continues to evolve, we'll see a shift in its architecture. While generative AI relies on probabilistic logic and chat-based interaction, Semantic AI will focus on structured data and deterministic logic. Structured data isn't just a business need for HR to generate reports; it also helps us understand and feel informed about the consequences of our requests (such as unpaid leave, price change), making interactions with AI meaningful and effective.
Once the generative AI hype settles, we believe the true power of AI will lie in extracting structured data rather than generating a "word salad." As AI continues to evolve, we'll see a shift in its architecture. While generative AI relies on probabilistic logic and chat-based interaction, Semantic AI will focus on structured data and deterministic logic. Structured data isn't just a business need for HR to generate reports; it also helps us understand and feel informed about the consequences of our requests (such as unpaid leave, price change), making interactions with AI meaningful and effective.
In the 2018 World Chess Championship, Magnus Carlsen and Fabiano Caruana's game ended in a draw despite Caruana's material advantage. Stockfish, the powerful chess engine, revealed a stunning missed opportunity: a forced checkmate in 35 moves.
Stockfish's analysis suggested unconventional moves, like trapping the Knight on the edge of the board—moves no human would consider. This showcased Stockfish's ability to see far beyond human intuition, highlighting the power of AI in uncovering deep, hidden strategies in chess, even outwitting the world's best players.
Stockfish is a narrow AI with a rating estimated to be over 3500. This is significantly higher than Magnus Carlsen’s rating of 2882. Within its specific domain, Stockfish demonstrates superintelligent behavior. This trend is likely to happen in other fields, such as programming and customer support, where AI could surpass the world's best experts. If we extrapolate this trend, we can predict three outcomes:
1. AI will enhance, not replace human expertise
To improve their game, players use Stockfish to analyze their chess moves. This has contributed to the growth of top chess players, since its launch in 2008:
Decade | Grandmasters | International Masters | FIDE Masters | Candidate Masters |
|---|---|---|---|---|
1970s | 82 | 200 | 500 | 500 |
1980s | 300 | 400 | 1000 | 1000 |
1990s | 600 | 800 | 2000 | 2000 |
2000s | 1000 | 1500 | 3500 | 3000 |
2010s | 1500 | 2000 | 5000 | 4000 |
2020s | 1722 | 2400 | 6000 | 5000 |
Similarly, top performers in different fields will increase, not decrease with AI. AI will teach us to be superhumans. On platforms like Chess.com, you can play for free but pay to improve your game using Stockfish. Similarly, future apps might be free, but you might pay for AI-driven learning. Edtech might not be a separate vertical; it could be the premium version in all verticals.
2. AI automation might be considered cheating
Using Stockfish in competition is considered cheating. In the 2022 Sinquefield Cup, World Chess Champion Magnus Carlsen resigned, suspecting his opponent, Hans Niemann, of using Stockfish. This caused a stir in the chess world, raising concerns about the impact of technology. The same might happen with AI assistants. Using AI to learn might be the norm, but delegating your work to AI could be frowned upon like cheating. AI would be a teacher, not a proxy who writes exam for you. If you are rebranding your product as AI, you might want to hold your horses. Investors might like it, but customers may not.
Note: For people who think customers care only about the output, this didn't happen in chess. We don't watch Stockfish vs. Magnus Carlsen games. Magnus Carlsen is the star we celebrate, not Stockfish.
3. Super intelligence could be deterministic
In the endgame, Stockfish acts like a deterministic algorithm, using precomputed tablebases to make perfect moves with absolute certainty. This capability outstrips even Magnus Carlsen, as Stockfish can foresee and execute a flawless 35-move checkmate sequence that no human could match. This combination of a probabilistic middle game and a deterministic endgame makes it unbeatable.
AI will hit a plateau once LLMs have read all available text and reach the IQ of top experts in various fields. However, just as Stockfish has surpassed Carlsen's rating of 2882 through the use of deterministic algorithms, artificial superintelligence could achieve unprecedented levels of capability by combining the adaptability of probabilistic LLMs with the precision of deterministic systems. Given that deterministic systems have a 50-year head start over probabilistic LLMs, this hybrid approach could excel at both nuanced tasks and well-defined problems, ultimately surpassing human capabilities across many domains.
Conclusion
Ten years ago, I predicted the impact of AI on CRM and other business sectors. Most of these predictions have come true, except for the widespread combination of rule engines with machine learning. If chess is a leading indicator, I still believe that superintelligence will combine deterministic algorithms and probabilistic LLMs, excelling at both structured and nuanced tasks. Its adoption in chess not only showcases technological prowess but also provides a blueprint for thriving with superintelligence instead of being scared about it.
Both first-time and second-time founders often don’t know what they’re doing. However, first-time founders believe they must appear knowledgeable, so they pretend to have all the answers in front of their employees. This act contributes to their feeling of being impostors—the more they pretend, the more they feel like frauds.
Second-time founders understand that all founders are in the same situation of not knowing everything. This realization leads them not to feel obliged to act as if they have all the answers. They are more open about their uncertainties with their employees and investors, which is why they come across as more authentic.
The advantage of being in accelerators like YC is that first-time founders can realize they don’t need to know everything. They see that their heroes—alums, investors, mentors—don’t have all the answers either. They offer suggestions, not definitive answers, which instead of being a disappointment, shows first-time founders that everyone is in the same boat. It’s better to be authentic and seek answers from their own experiences. This is a major benefit of being in a community such as YC or in a city like San Francisco.
Code Generation AI is all the rage these days. But is generating code for programming languages like JavaScript and Python the right path to take? I think not. I think we should be generating code for declarative languages like Excel or SQL.
What's the difference, you ask?
In declarative languages, you express what your intention is. For example, in Excel, you can use SUM() to add all the line items and calculate the order amount. If the quantity of a line item changes, it will automatically recalculate the line item amount and then invoke SUM() to recalculate the order amount. But in imperative languages like JavaScript or Python, you instruct the computer on how to calculate the order amount. You would implement a function to add the line items as the order amount. Anytime the quantity of a line item changes, it is your job to call the function and recalculate the order amount.
Why is this important?
If you are asking AI to generate code for your requirements, you are essentially expressing your intent. So, expressing it in a declarative language seems natural. This will help the person who gave the requirement to understand the code generated by the AI. On the other hand, generating code for a programming language seems like the worst form of leaky abstraction. "Leaky abstraction" describes a scenario where attempts to simplify a system end up requiring users to understand its underlying complexities to troubleshoot it. Code generation can automate the creation process. But, the resulting code can be a puzzle even to a skilled developer who is debugging it. The person who gave the requirement will most likely not understand any of it.
So, why do AI companies generate code like this?
I guess it comes down to the availability of training data for AI. There are a lot of open-source projects in JavaScript or Python, so it is easy to train AI with it. But open-source projects in Excel are almost non-existent. So, the unavailability of training data might be the primary reason behind the direction these code generation AI companies are taking. At Neartail, we are taking a middle road. We have created a declarative language using JavaScript syntax so that we could train the AI as well as make it understandable to business owners. Will other AI companies realize the perils of leaky abstraction and change its course? Only time will tell.
School grade is measure of our knowledge in a subject.
SEO traffic is a measure of the usefulness of our content to others.
Money is a measure of the usefulness of our work to others.
Unfortunately, they can be inaccurate reflections of our contributions. For example, we can memorize a subject without truly understanding it and still receive good grades. When these measures are widely accepted as authoritative, companies may recruit based on grades rather than actual knowledge, leading us to study for grades rather than for understanding. Similar issues occur with SEO and money. Money is meant to measure how useful our work is to others, but over time, it has become something people chase for its own sake. Inheritance and financial tricks allow people to collect wealth without necessarily contributing value, distorting what money is supposed to represent. But the alternatives (such as socialism) are terrible as well. Eventually, most of us end up chasing the measure instead of the outcomes, which leads to gaming the system.